Quick Information/Overview
| Pattern Type |
Structural |
| Applicable Language/Framework |
Agnostic OOP |
| Pattern Source |
Gang of Four |
| Difficulty |
Somewhat complex to grasp, moderate to implement. |
Up Front Definitions
There are no special definitions that I’ll use here not defined inline.
The Problem
The iconic example of a situation in which the Bridge pattern is applicable is modeling a wall switch and the thing that it controls. Let’s say that you start out with a set of requirements that says users want to be able to turn an overhead light on and off. Skipping right to implementation, you do something like this:
public class OverheadLamp
{
public bool IsOn { get; private set; }
public bool IsUp { get; private set; }
public void FlipSwitch()
{
IsUp = !IsUp;
IsOn = !IsOn;
}
}
This is fine, and you deliver it to production, and everyone is happy. But in the next iteration, a new requirement comes in that users want to be able to use a rocker switch or a push-button switch. And just as you’re getting ready to implement that, you’re also told that you need to implement a rotary switch (like a door deadbolt, you turn this to two different positions). Well, that’s fine, because you have just the trick up your sleeve in a polymorphic language: the interface!
public interface IOverheadLamp
{
bool IsOn { get; }
void OperateSwitch();
}
public class RockerOperatedLamp : IOverheadLamp
{
public bool IsOn { get; private set; }
public bool IsUp { get; private set; }
public void OperateSwitch()
{
IsUp = !IsUp;
IsOn = !IsOn;
}
}
public class PushButtonOperatedLamp : IOverheadLamp
{
public bool IsOn { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
}
}
public class RotarySwitchOperatedLamp : IOverheadLamp
{
public bool IsOn { get; private set; }
public bool IsToTheLeft { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
IsToTheLeft = !IsToTheLeft;
}
}
Notice the change in “FlipSwitch” to the more abstract “OperateSwitch()”. This allows for implementations where the switch is not “flipped,” such as push-button. (I’m not really a stickler for English semantics, but I suppose it’s debatable whether or not a rotary switch’s operation would be a “flip.”)
Now you’re all set. Not only does your overhead lamp operate with several different kinds of switches, but you’re following the Open/Closed Principle. Marketing can come in and demand a toggle switch, a fancy touchpad, or even a contraption that you smack with a hammer, and you handle it by writing and unit-testing a new class. Everything looks good.
Except in the next iteration, those crafty marketing people realize that a switch could operate other kinds of electronics, like fans, appliances, and space heaters. So they tell you that they want the switch now to be able to turn on and off computers as well as overhead lamps. That’s a challenge, but you’re up to it. You have your interface, so you’ll just add some more polymorphs and refine the abstraction a bit:
public interface ISwitchableAppliance
{
bool IsOn { get; }
void OperateSwitch();
}
public class RockerOperatedLamp : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public bool IsUp { get; private set; }
public void OperateSwitch()
{
IsUp = !IsUp;
IsOn = !IsOn;
}
}
public class PushButtonOperatedLamp : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
}
}
public class RotarySwitchOperatedLamp : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public bool IsToTheLeft { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
IsToTheLeft = !IsToTheLeft;
}
}
public class RockerOperatedComputer : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public bool IsUp { get; private set; }
public void OperateSwitch()
{
IsUp = !IsUp;
IsOn = !IsOn;
}
}
public class PushButtonOperatedComputer : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
}
}
public class RotarySwitchOperatedComputer : ISwitchableAppliance
{
public bool IsOn { get; private set; }
public bool IsToTheLeft { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
IsToTheLeft = !IsToTheLeft;
}
}
Alright, that code is going to work, but you’re a little leery of the fact that, after renaming IOverheadLamp to ISwitchableAppliance, the new classes you created were simply a result of copying and pasting the lamp classes and changing “lamp” to “computer.” You should be leery. That’s a design/code smell (duplication–don’t repeat yourself!) But whatever–you’re behind schedule and people are giving you a hard time. You can refactor it later.
Now the next iteration starts, and marketing is wildly pleased with your computer/light switch. They want to be able to control any sort of appliance that you can imagine–the aforementioned space heaters, ceiling fans, refrigerators, plug-in light sabers, whatever. Oh, and by the way, computers don’t necessarily turn on when you flip the switch for the outlet that they’re plugged into, so can you have the computer not turn on when you turn the switch on, but turn off when you turn the switch off? Oh, and remember that hammer-operated switch? They want that too.
Well, you’re hosed. You realize that you’re going to have to copy and paste your three (four, with the hammer thing) classes dozens or hundreds of times, and you’re going to have to change the behavior of some of them. All of the computer ones, for instance, don’t automatically turn on when you activate the switch. But clients of your code don’t know that, so they’re now going to have to try to cast the ISwitchableAppliance to one of the classes ending in Computer to account for its special behavior. This just got ugly, and fast.
So, What to Do?
In terms of realizing what you should have done or what can be done, the first important thing to realize is that you’re dealing with two distinct concepts rather than just one. Consider the following two diagrams:

Our current object model
Another way of looking at things
The first diagram is what we were doing. Conceptually, every appliance consists not only of the appliance itself, but also of the switch that turns it on or off (or does something to it, more generally). In the second diagram, we’ve separated those concerns, realizing that the appliance itself and the switching mechanism are two separate entities capable of varying independently.
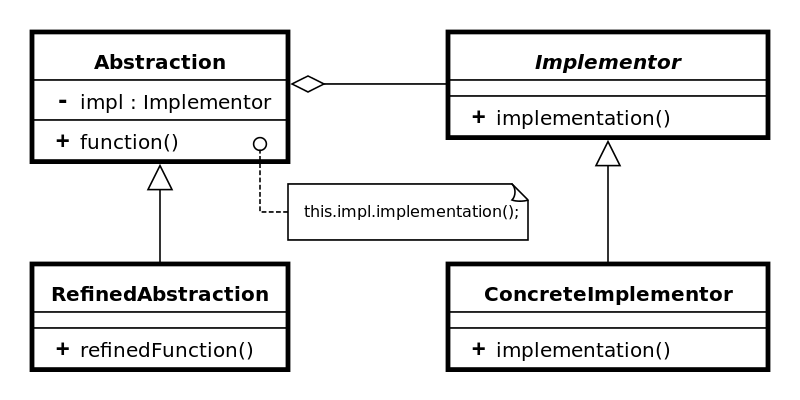
At this point, I’ll introduce the Bridge pattern in earnest, in a UML diagram, compliments of Wikipedia:
In looking at this version of it, we see some new concepts introduced: abstraction and implementor. I’ll explain the theory behind this in the next section, but suffice it to say for now that our abstraction is the switch and our implementor is the appliance. As the diagram depicts, our clients are going to deal with the abstraction, and they’re going to do so by handing it a reference to the implementor that they want. More concretely, our clients are going to instantiate some switch and tell it what device they want it to control.
By way of code, let’s consider what we had before marketing buried us with the latest barrage of requirements–three switch types and two appliances. The only new requirement that we’ll consider up front is the one suggesting that computers need to behave differently than other appliances when the switch controlling them is toggled. First, we’ll define the API for the switch (abstraction) and the appliance (implementation):
public interface ISwitch
{
bool IsOn { get; }
IAppliance Appliance { get; set; }
void OperateSwitch();
}
public interface IAppliance
{
bool HasPower { get; }
bool IsOn { get; }
void TogglePower();
void ToggleOn();
}
Notice that because our implementation up until this point has been pretty simple, the interfaces look almost identical (minus the HasPower, TogglePower() in IAppliance, which we’ve added with our new requirement in mind). Both the appliance and the switch have the concept of on and off, more or less. This similarity was what allowed us, up until now, to operate under the (faulty) assumption that these two concepts could easily be combined. But we ran into difficulty when we saw that the abstraction and the implementation needed to vary separately (more on this later).
Where we got into trouble was with the concept of toggle power and distinguishing between having power and being on. That makes sense for an appliance (is it turned off or unplugged?) but not for a switch, which only knows that it has two positions and that it’s in one of them. So, with the introduction of this new requirement, we can no longer operate under even the pretense that mashing these two concepts together is a reasonable thing to do.
The key thing to notice here is that ISwitch has a reference to an IAppliance. This means that clients instantiating a switch can hand it an appliance on which to operate. But we’ll look at client code later.
Now let’s consider the implementors of IAppliance:
public class OverheadLamp : IAppliance
{
public bool HasPower { get; private set; }
public bool IsOn { get; private set; }
// Supplying power to lamps automatically turns them on, and removing it turns them off
// (well, probably only if their onboard switch is in that position, but that's tangential to the example)
public void TogglePower()
{
HasPower = !HasPower;
ToggleOn();
}
public void ToggleOn()
{
IsOn = !IsOn;
}
}
public class Computer : IAppliance
{
public bool HasPower { get; private set; }
public bool IsOn { get; private set; }
// Toggling power for computer just turns it off if it was on
public void TogglePower()
{
HasPower = !HasPower;
if (!HasPower)
{
IsOn = false;
}
}
public void ToggleOn()
{
IsOn = !IsOn;
}
}
Here, notice the distinction in the behavior of TogglePower(). For lamps, supplying or removing power supplies and removes power but also turns the lamp on and off, respectively. For computers, removing power turns the computer off, but supplying power does not turn it on. (Some other client of the API will have to do that manually, ala real life.) Now that we’ve decoupled the actual implementation of the concept of appliances being on and off from the abstraction of initiating that implementation, our appliances can change how they behave when power is supplied or removed. We could introduce a new appliance, “BatteryPoweredAlarmClock,” that didn’t turn off when power was cut (or, more accurately, kicked off some long running timer that would turn it off at some point later).
Here are the implementations of the ISwitch interface:
public class Rocker : ISwitch
{
public bool IsOn { get; private set; }
public IAppliance Appliance { get; set; }
public bool IsUp { get; private set; }
public void OperateSwitch()
{
IsUp = !IsUp;
IsOn = !IsOn;
if (Appliance != null)
{
Appliance.TogglePower();
}
}
}
public class PushButton : ISwitch
{
public bool IsOn { get; private set; }
public IAppliance Appliance { get; set; }
public void OperateSwitch()
{
IsOn = !IsOn;
if (Appliance != null)
{
Appliance.TogglePower();
}
}
}
public class Rotary : ISwitch
{
public bool IsOn { get; private set; }
public IAppliance Appliance { get; set; }
public bool IsToTheLeft { get; private set; }
public void OperateSwitch()
{
IsOn = !IsOn;
IsToTheLeft = !IsToTheLeft;
if (Appliance != null)
{
Appliance.TogglePower();
}
}
}
Notice that the individual implementors still retain their own unique properties. Rocker still has up or not up, and Rotary still has its position. But the things that all share are implementations of the OperateSwitch() method, the IsOn property (it might be more accurate to rename this “IsInOnPosition” to avoid confusion with the appliance On/Off state, but I already typed up the code examples), and the IAppliance property. In addition, all of them operate on the appliance’s TogglePower() method.
This last distinction is important. Switches, in concept, can only supply power to an appliance or take it away–they don’t actually switch it on and off. It is up to the appliance to determine how it behaves when power is supplied or removed. As this implementation is continued, it is important to remember this distinction. I could have omitted ToggleOn() from the appliances’ interface if this code were in a vacuum because the switch has no use for it. However, assuming that we’re modeling something a little broader (like, say, my home automation pet project), we clearly want people in houses to be able to turn on their computers and televisions. The switch is unlikely to be the only consumer of IAppliance.
Finally, let’s consider how we would use this thing:
public class Client
{
public IAppliance WireUpAComputerAndFlipTheSwitch(ISwitch switchToUse)
{
var mySwitch = switchToUse ?? new Rocker(); //If the switch passed in is null, use a rocker by default
mySwitch.Appliance = new Computer(); //Wire the switch up to a new computer
mySwitch.OperateSwitch(); //Operate the switch
return mySwitch.Appliance; //Return the appliance in whatever state the switch operation put it
}
}
Here’s an example application, cutting out any considerations like factory classes or methods. We have some method that takes a switch as input and returns a computer in the state the method put it in. Conceptually, this is pretty simple–we’ve done all the hard work. You just take your switch, set it to operate some appliance, and then operate away.
A More Official Explanation
Earlier, I mentioned the notion of decoupling an abstraction from its implementation. This is the backbone of this pattern, but it might be a little confusing in terms of what it’s actually trying to communicate. I’d imagine some reading will think, “Isn’t decoupling an abstraction from its implementation what an interface contract does? Why the separate pattern?”
To answer that first question, I’ll say, “yes.” Defining an interface says, “Any implementors of this interface will define a method that takes these parameters and returns this type of value, and the details are up to the implementor to sort out. The client doesn’t care how–just get it done.” So, in a manner of speaking, the method signature is the abstraction and the implementation is, well, the implementation.
The problem is that this is a code abstraction rather than a modeled abstraction. That is, a method signature is a contract between one developer and another and not between two different objects. A switch isn’t an interface to a device in C#–it’s an interface to a device in the real world. A switch has its own properties, operations, and state that needs to be modeled. It can’t be reduced in code to a method signature.
So what are we getting at when we say that we want to decouple an abstraction from an implementation? Generally speaking, we’re saying that we want to decouple a thing of some sort from operation performed on that thing. In our example, the thing is an appliance, and the operations performed on it are supplying or removing power. The switch (abstraction) is a separate object with its own properties that needs to be modeled. And what’s more, we can have different kinds of switches, so long as all of the switches perform the needed operation on appliance.
In general, the Bridge pattern represents a scenario like a simple sentence with subject, verb, object: Erik eats apple. We could code up Erik and code up an apple. But then maybe Erik eats orange. So we define a fruit base class or interface and model the world with “Erik eats fruit.” But then maybe Joe also eats fruit, so we need to define a person class and further generalize to “Person eats fruit.” In this case, our abstraction is person, and our implementation is fruit. Person has a fruit property and performs “Eat” on it. The one thing that never changed as we continued generalizing was “eat”–it was always “A eats B.” Going back to our switch/appliance paradigm, we notice the same thing: “A toggles power to B.”
The decoupling allows us to have different subjects and for different objects to behave differently during the course of the verb operation. So if I use the Bridge pattern to model “Person eats Fruit,” it isn’t hard to specify that some fruits leave a pit or a core and some don’t following the eat operation. It isn’t hard to have some people get indigestion as a result of eating fruit. And neither one of those new requirements merits a change to the other one. Fruit doesn’t change if it gives people indigestion, and a person isn’t changed when a piece of fruit they eat has a pit.
Other Quick Examples
The Bridge pattern has as many uses as you can conceive of “A verb B” pairs that might have some variance in the A and B, so I’ll list a handful that lend themselves well to the pattern.
- You have images stored in different formats on disk (bmp, jpg, png, etc) and you also have different ways of rendering images (grayscale, inverted, etc)
- You’re performing a file operation on a file that may be a Windows, Mac, or Linux file
- You have different types of customers that can place different types of orders
- You have a GUI that displays buttons, text boxes, and labels differently depending on different user themes
A Good Fit–When to Use
The Bridge Pattern makes sense to use when you have two objects participating in an action and the mechanics of that action will have different ramifications for different types of the participating objects. But, beyond that simple distinction, it makes sense when you are likely to need to add participants. In our example, different appliances behaved differently when power was supplied or removed, and different switches had different behaviors and properties surrounding their operation. Additionally, it seemed pretty likely after the first round or two of marketing requests that we’d probably be adding more “subjects” and “objects” in perpetuity.
This is where the Bridge pattern really shines. It creates a situation where those types of requirements changes mean adding a class, rather than changing existing ones. And, it obviates duplicating code with copy and paste.
I’d summarize here by saying that the Bridge pattern is a good fit when you are modeling “A action B,” when A and B vary in how the action affects each one, and when you find that coupling A and B together will result in duplication. Conversely, it might be a good pattern to look at when you’re faced with the prospect of a combinatorial explosion of implementations as requirements change. That is, you can tell that A and B should be decoupled if you find yourself with classes like A1B1, A1B2, A2B1, A2B2.
Square Peg, Round Hole–When Not to Use
Don’t use this pattern if A and B are really appropriately coupled. If, in your object model, switches were actually wired to appliances, our effort would be unnecessary. Conceptually, it wouldn’t be possible to use one appliance’s switch on another–each appliance would come with one. So you define the different types of switches, give each appliance a concrete switch, and define “TurnOn” and “TurnOff” as methods on the appliance. The Bridge pattern is meant to be used when real variance occurs between the actors involved, not to be used any time one thing performs an operation on another.
There’s always YAGNI to consider as well. If the requirements had stayed as they were early in our example–we were only interested in lights–the pattern would be overkill. If you’re writing a utility specifically to model the overhead lights in a house, why define IAppliance and other appliances only to let them languish as dead code? Apply the bridge when you start getting actual variance in both objects, not when you just think it might happen at some point. In the simplest application, having to supply Switch with your only appliance, “OverheadLamp,” is wasteful and confusing.
Finally, Bridge has a curious relationship with Adapater, which I covered earlier. Adapater and Bridge have conceptual similarities in that they both link two objects and allow them to vary independently. However, Adapter is a retrofit hack used when your hands are tied, and Bridge is something that you plan when you control everything. So, don’t use (or try to use) Bridge when you don’t control one of the participant hierarchies. If, say, “RockerSwitch” et. al. were in some library that you didn’t control, there’s no point bothering to try a bridge. You’d need to adapt, rather than bridge, the switches to work in your implementation.
So What? Why is this Better?
So, why do all this? We’ve satisfied the requirement about computers behaving differently when the switch is flipped, but was it worth it? It sure was. Consider how the new requirements will now be implemented. Marketing wants 100 new appliances and a new switch. Sure, it’s a lot of work–we have to code up 101 new classes (100 for the appliances and 1 for the switch). But in the old, mash-up way, we’d have to code up those 100 new appliance classes, copy and paste them 3 times each, code up a new switch class, and copy and paste it 102 times, for a total of 403 new classes. And what if we made a mistake in a few of the appliance classes? Well, we’d have to correct each one 4 times because of all the copy/pasted code. So, even if the idea that not duplicating your work doesn’t sell you, the additional development and maintenance should.