There is No Such Thing as Waterfall
Don’t try to follow the waterfall model. That’s impossible. Instead, only try to realize the truth: there is no waterfall.

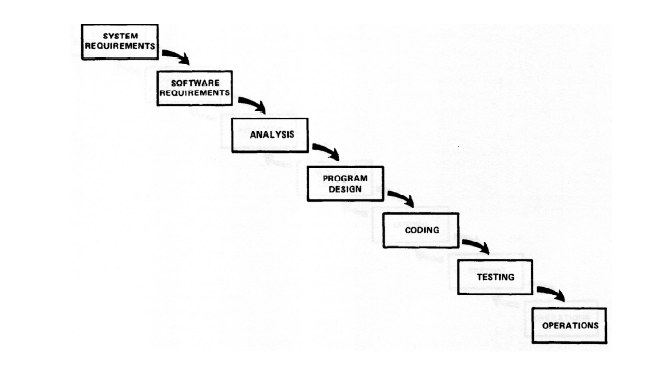
Waterfall In Practice Today
I often see people discuss, argue and debate the best approach or type of approach to software development. Most commonly, this involves a discussion of the merits of iterative and/or agile development, versus the “more traditional waterfall approach.” What you don’t see nearly as commonly, but do see every now and then is how the whole “waterfall” approach is based on a pretty fundamental misunderstanding, wherein the man (Royce) who coined the term and created the iconic diagram of the model was holding it up as a strawman to say (paraphrased) “this is how to fail at writing software — what you should do instead is iterate.” Any number of agile proponents may point out things like this, and it isn’t too hard to make the case that the waterfall development methodology is flawed and can be problematic. But, I want to make the case that it doesn’t even actually exist.
I saw a fantastic tweet earlier from Energized Work that said “Waterfall is typically 6 months of ‘fun up front’, followed by ‘steady as she goes’ eventually ramping up to ‘ramming speed’.” This is perfect because it indicates the fundamental boom and bust, masochistic cycle of this approach. There is a “requirements phase” and a “design phase”, which both amount basically to “do nothing for a while.” This is actually pretty relaxing (although frustrating for ambitious and conscientious developers, as this is usually unstructured-unstructured time). After a few weeks or months or whatever of thumb-twiddling, development starts, and life is normal for a few weeks or months while the “chuck it over the wall” deadline is too far off for there to be any sense of how late or bad the software will turn out to be. Eventually, though, everyone starts to figure out that the answers to those questions are “very” and “very”, respectively, and the project kicks into a death march state and “rams” through the deadline over budget, under-featured, and behind schedule, eventually wheezing to some completion point that miraculously staves off lawyers and lawsuits for the time being.
This is so psychically exhausting to the team that the only possible option is 3 months of doing nothing, er, excuse me, requirements and design phase for the next project, to rest. After working 60 hour weeks and weekends for a few weeks or months, the developers on the team look forward to these “phases” where they come in at 10 AM, leave at 4 PM, and sit around writing “shall” a lot, drawing on whiteboards, and googling to see if UML has reached code generation Shangri La while they were imprisoned in their cubicles for the last few months. Only after this semi-vacation are they ready to start the whole chilling saga again (at least the ones that haven’t moved on to greener pastures).
Diving into the Waterfall
So, what actually happens during these phases, in a more detailed sense, and what right have I to be so dismissive of requirements and design phases as non-work? Well, I have experienced what I’m describing firsthand on any number of occasions, and found that most of my time is spent waiting and trying to invent useful things to do (if not supporting the previous release), but I realize that anecdotal evidence is not universally compelling. What I do consider compelling is that after these weeks or months of “work” you have exactly nothing that will ever be delivered to your end-users. Oh, you’ve spent several months planning, but when was the last time planning something was worked at anywhere near as much as actually doing something? When you were a high school or college kid and given class time to make “idea webs” and “outlines” for essays, how often was that time spent diligently working, and how often was that time spent planning what to do next weekend? It wasn’t until actual essay writing time that you stopped screwing around. And, while we like to think that we’ve grown up a lot, there is a very natural tendency to regress developmentally when confronted with weeks of time after which no real deliverable is expected. For more on this, see that ambitious side project you’ve really been meaning to get back into.
But the interesting part of this isn’t that people will tend to relax instead of “plan for months” but what happens when development actually starts. Development starts when the team “exits” the “design phase” on that magical day when the system is declared “fully designed” and coding can begin. In a way, it’s like Christmas. And the way it’s like Christmas is that the effect is completely ruined in the first minute that the children tear into the presents and start making a mess. The beautiful design and requirements become obsolete the second the first developer’s first finger touches the first key to add the first character to the first line of code. It’s inevitable.
During the “coding phase”, the developers constantly go to the architect/project manager/lead and say “what about when X happens — there’s nothing in here about that.” They are then given an answer and, if anyone has time, the various SDLC documents are dutifully updated accordingly. So, developers write code and expose issues, at which time requirements and design are revisited. These small cycles, iterations, if you will, continue throughout the development phase, and on into the testing phase, at which time they become more expensive, but still happen routinely. Now, those are just small things that were omitted in spite of months of designing under the assumption of prescience — for the big ones, something called a “change request” is required. This is the same thing, but with more emails and word documents and anger because it’s a bigger alteration and thus iteration. But, in either case, things happen, requirements change, design is revisited, code is altered.
Whoah. Let’s think about that. Once the coding starts, the requirements and design artifacts are routinely changed and updated, the code changes to reflect that, and then incremental testing is (hopefully) done. That doesn’t sound like a “waterfall” at all. That sounds pretty iterative. The only thing missing is involving the stakeholders. So, when you get right down to it, “Waterfall” is just dysfunctional iterative development where the first two months (or whatever) are spent screwing around before getting to work, where iterations are undertaken and approved internally without stakeholder feedback, and where delivery is generally late and over budget, probably by an amount in the neighborhood of the amount of time spent screwing around in the beginning.

The Take-Away
My point here isn’t to try to persuade anyone to alter their software development approach, but rather to try to clarify the discussion somewhat. What we call “waterfall” is really just a specifically awkward and inefficient iterative approach (the closest thing to an exception I can think of is big government projects where it actually is possible to freeze requirements for months or years, but then again, these fail at an absolutely incredible rate and will still be subject to the “oh yeah, we never considered that situation” changes, if not the external change requests). So there isn’t “iterative approach” and “waterfall approach”, but rather “iterative approach” and “iterative approach where you procrastinate and scramble at the end.” And, I don’t know about you, but I was on the wrong side of that fence enough times as a college kid that I have no taste left for it.
 I believe that this mystifying behavior has two main sources of persistence as a mainstay in the human condition. The first is that without careful consideration, we tend toward logical fallacy and this is an example of the fallacy
I believe that this mystifying behavior has two main sources of persistence as a mainstay in the human condition. The first is that without careful consideration, we tend toward logical fallacy and this is an example of the fallacy 
 The parallels here are rather striking if you omit the portions of Scrum that have to do with collaboration and those types of logistics. When starting on a task, I think of the first few things that I’ll need to do and those go on the list. I prioritize them by putting the most important (usually the ones that will block progress on anything else) at the top, but I don’t really spend a lot of time on this, opting to revise or refine it if and when I need to. Any new item on the list is yellow and when done, I turn it green.
The parallels here are rather striking if you omit the portions of Scrum that have to do with collaboration and those types of logistics. When starting on a task, I think of the first few things that I’ll need to do and those go on the list. I prioritize them by putting the most important (usually the ones that will block progress on anything else) at the top, but I don’t really spend a lot of time on this, opting to revise or refine it if and when I need to. Any new item on the list is yellow and when done, I turn it green.  In honor of this mystery person in my attic and my own natural tendency over the course of time toward more and more documentation, I’ve decided to start my own “developer” journal and I’ve logged my first entries this week. The journal is just a Word document at the moment, so I’m getting back to basics from my previous ascent through Excel, Mediawiki and WordPress, but I think this is good. All of those recording forms have a tendency toward hierarchical or formal organization that I don’t really want here. This is like me jotting notes during meetings in a notebook, but with less “action item: give Bill the TPS reports” and more “I just spent an hour trying to figure out why my CSS file was triggering an error and it turned out to be unrelated problem X in reality”.
In honor of this mystery person in my attic and my own natural tendency over the course of time toward more and more documentation, I’ve decided to start my own “developer” journal and I’ve logged my first entries this week. The journal is just a Word document at the moment, so I’m getting back to basics from my previous ascent through Excel, Mediawiki and WordPress, but I think this is good. All of those recording forms have a tendency toward hierarchical or formal organization that I don’t really want here. This is like me jotting notes during meetings in a notebook, but with less “action item: give Bill the TPS reports” and more “I just spent an hour trying to figure out why my CSS file was triggering an error and it turned out to be unrelated problem X in reality”. 

{kind=link}